hive是如何與hadoop結合的����?hive的架構大致構成是?hive的運行流程是���?
來源:北大青鳥總部
2020年01月14日 14:27
摘要:
hive是如何與hadoop結合的�?hive的架構大致構成是?hive的運行流程是���?
最近小編的一位朋友小華學習了hiveSQL的一些常見場景及應用,也通過很多示例做了大量練習��, 在心態(tài)上有一點小飄了�����,于是前兩天去面試了一家大數(shù)據(jù)公司��。 面試官一開始也是給面子����,問了hiveSQL操作窗口函數(shù)的兩道SQL題,小華都毫無疑問做出來了���,心里正美著的時候�����,面試官來了hive的靈魂三問:hive是如何與hadoop結合的���?hive的架構大致構成是���?hive的運行流程是?于是傻眼的小華面試完之后來找到小編����,希望小編能夠說一下hive這方面的內(nèi)容。
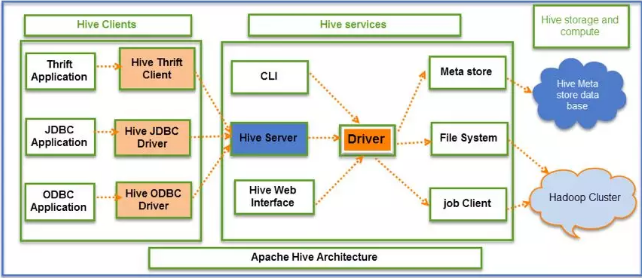
要說明白hive的整體工作流程��,首先需要了解一下hive的架構設計
一����、Hive Clients,Hive客戶端����,它為不同類型的應用程序提供不同的驅動,使得Hive可以通過類似Java��、Python等語言連接���,同時也提供了JDBC和ODBC驅動��。
二�、Hive Services,Hive服務端����,客戶端必須通過服務端與Hive交互,主要包括:
1.用戶接口組件(CLI����,HiveServer����,HWI),它們分別以命令行����、與web的形式連接Hive。
Driver組件�,該組件包含編譯器、優(yōu)化器和執(zhí)行引擎���,它的作用是將hiveSQL語句進行解析�、編譯優(yōu)化����、生成執(zhí)行計劃��,然后調(diào)用底層MR計算框架��。
2.Metastore組件�,元數(shù)據(jù)服務組件�。Hive數(shù)據(jù)分為兩個部分,一部分真實數(shù)據(jù)保存在HDFS中���,另一部分是真實數(shù)據(jù)的元數(shù)據(jù)��,一般保存在MySQL中����,元數(shù)據(jù)保存了真實數(shù)據(jù)的很多信息��,是對真實數(shù)據(jù)的描述����。
三、Hive Storage and Computing �,包括元數(shù)據(jù)存儲數(shù)據(jù)庫和Hadoop集群。Hive元數(shù)據(jù)存儲在RDBMS中��,Hive數(shù)據(jù)存儲在HDFS中���,查詢由MR完成�����。
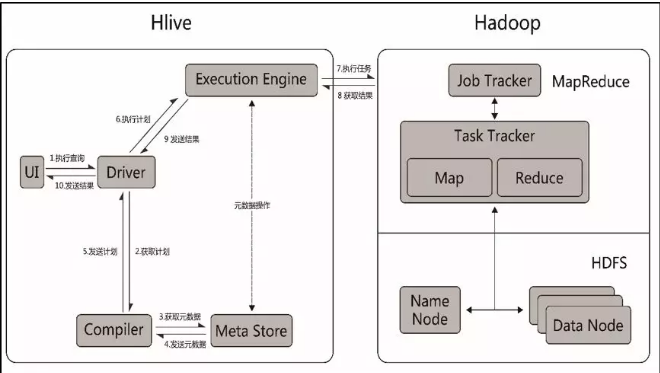
對Hive整體架構設計有一定了解之后����,我們再來看看Hive實際的工作流程
簡而言之����,Hive接到命令之后,首先會去元數(shù)據(jù)庫獲取元數(shù)據(jù)���,然后把元數(shù)據(jù)信息和作業(yè)計劃發(fā)送Hadoop集群執(zhí)行任務,再將最終的結果返回�。




 手機端官網(wǎng)
手機端官網(wǎng)


 京公網(wǎng)安備 11010802020714號
京公網(wǎng)安備 11010802020714號